Warning
The documentation here may not directly apply to your version of Flight, locate your version of Flight here
Cluster job schedulers¶
What is a batch job scheduler?¶
Most existing High-performance Compute Clusters are managed by a job scheduler; also known as the batch scheduler, workload manager, queuing system or load-balancer. The scheduler allows multiple users to fairly share compute nodes, allowing system administrators to control how resources are made available to different groups of users. All schedulers are designed to perform the following functions:
- Allow users to submit new jobs to the cluster
- Allow users to monitor the state of their queued and running jobs
- Allow users and system administrators to control running jobs
- Monitor the status of managed resources including system load, memory available, etc.
When a new job is submitted by a user, the cluster scheduler software assigns compute cores and memory to satisfy the job requirements. If suitable resources are not available to run the job, the scheduler adds the job to a queue until enough resources are available for the job to run. You can configure the scheduler to control how jobs are selected from the queue and executed on cluster nodes, including automatically preparing nodes to run parallel MPI jobs. Once a job has finished running, the scheduler returns the resources used by the job to the pool of free resources, ready to run another user job.
Types of compute job¶
Users can run a number of different types of job via the cluster scheduler, including:
- Batch jobs; single-threaded applications that run only on one compute core
- Array jobs; two or more similar batch jobs which are submitted together for convenience
- SMP or multi-threaded jobs; multi-threaded applications that run on two or more compute cores on the same compute node
- Parallel jobs; multi-threaded applications making use of an MPI library to run on multiple cores spread over one or more compute nodes
The cluster job-scheduler is responsible for finding compute nodes in your cluster to run all these different types of jobs on. It keeps track of the available resources and allocates jobs to individual groups of nodes, making sure not to over-commit CPU and memory. The example below shows how a job-scheduler might allocate jobs of different types to a group of 8-CPU-core compute nodes:
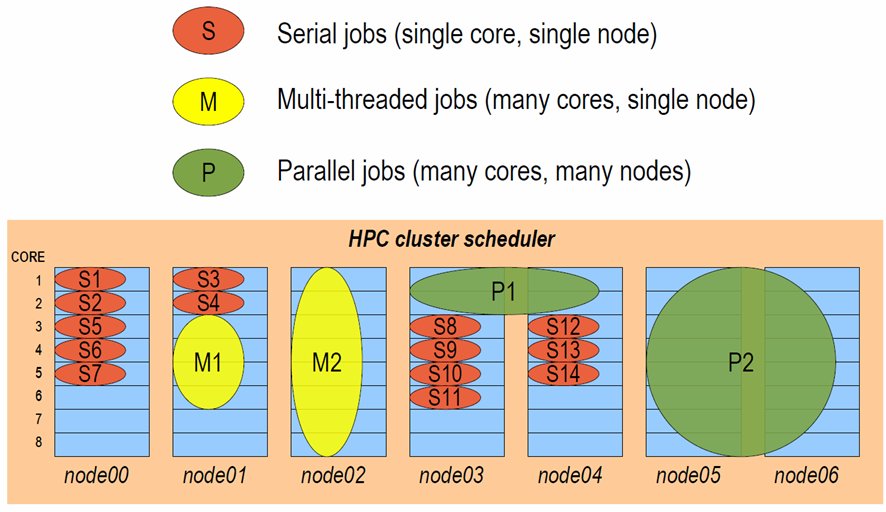
Interactive and batch jobs¶
Users typically interact with compute clusters by running either interactive or batch (also known as non-interactive) jobs.
- An interactive job is one that the user directly controls, either via a graphical interface or by typing at the command-prompt.
- A batch job is run by writing a list of instructions that are passed to compute nodes to run at some point in the future.
Both methods of running jobs can be equally as efficient, particularly on a personal, ephemeral cluster. Both classes of job can be of any type - for example, it’s possible to run interactive parallel jobs and batch multi-threaded jobs across your cluster. The choice of which class of job-type you want to use will depend on the application you’re running, and which method is more convenient for you to use.
Why use a job-scheduler on a personal cluster?¶
Good question. On shared multi-user clusters, a job-scheduler is often used as a control mechanism to make sure that users don’t unfairly monopolise the valuable compute resources. In extreme cases, the scheduler may be wielded by system administrators to force “good behaviour” in a shared environment, and can feel like an imposition to cluster users.
With your own personal cluster, you have the ability to directly control the resources available for your job - you don’t need a job-scheduler to limit your usage.
However - there are a number of reasons why your own job-scheduler can still be a useful tool in your cluster:
- It can help you organise multi-stage work flows, with batch jobs launching subsequent jobs in a defined process.
- It can automate launching of MPI jobs, finding available nodes to run applications on.
- It can help prevent accidentally over-allocating CPUs or memory, which could lead to nodes failing.
- It can help bring discipline to the environment, providing a consistent method to replicate the running of jobs in different environments.
- Jobs queued in the scheduler can be used to trigger scaling-up the size of your cluster, with compute nodes released from the cluster when there are no jobs to run, saving you money.
Your Alces Flight Compute cluster comes with a job-scheduler pre-installed, ready for you to start using. The scheduler uses very few resources when idle, so you can choose to use it if you find it useful, or run jobs manually across your cluster if you prefer.
Available cluster job schedulers¶
Alces Flight Compute Community Edition launches with a pre-configured SLURM environment - an open-source job scheduler. The syntax and usage of commands is available as part of the SLURM overview.
Alces Flight Compute can optionally be configured to launch the following cluster job schedulers;
- Open Grid Scheduler (SGE) - an open-source job scheduler, built from the codebase of what was originally the Sun Grid Engine (SGE)
- OpenLava scheduler (similar to IBM LSF)
- Torque scheduler
- PBS Pro scheduler
Job-scheduler configuration and support¶
Alces Flight Compute clusters are designed to pre-install your chosen cluster job scheduler, and make it available to use by the single-user configured at launch time. Customers are provided with dedicated support contacts to help out where needed. For full commercial code-base support for job-schedulers, please contact the vendor of your chosen software product.
It is also possible for users to download and install their own job-scheduler across their Flight Compute cluster - any product compatible with RedHat Enterprise Linux 7 operating system and derivatives should be possible to run on your cluster.