OpenLava Scheduler¶
The OpenLava cluster job-scheduler is an open-source IBM Platform LSF compatible job-scheduler. The syntax and usage of commands is identical to the IBM Platform LSF scheduler, and users can typically migrate from one to another with no issues. This documentation provides a guide to using OpenLava on your Alces Flight Compute cluster to run different types of jobs.
See Cluster job schedulers for a description of the different use-cases of a cluster job-scheduler.
Running an Interactive job¶
You can start a new interactive job on your Flight Compute cluster by using the following example command:
bsub -Is bash
The above command uses the following options in order to create an interactive job, with shell mode support:
-Is- Submits an interactive job and creates a pseudo-terminal when the job starts
bash- Choose the shell type to use when creating the interactive job
[alces@login1(scooby) ~]$ bsub -Is bash
Job <104> is submitted to default queue <normal>.
<<Waiting for dispatch ...>>
<<Starting on ip-10-75-1-61>>
[alces@ip-10-75-1-61(scooby) ~]$ module load apps/R
Installing distro dependency (1/1): tk ... OK
[alces@ip-10-75-1-61(scooby) ~]$ R
R version 3.3.0 (2016-05-03) -- "Supposedly Educational"
Copyright (C) 2016 The R Foundation for Statistical Computing
Platform: x86_64-pc-linux-gnu (64-bit)
Alternatively, an interactive session can also be executed from a graphical desktop session; the job-scheduler will automatically find an available compute node to launch the job on. Applications launched from within the interactive job session are executed on the assigned cluster compute node.
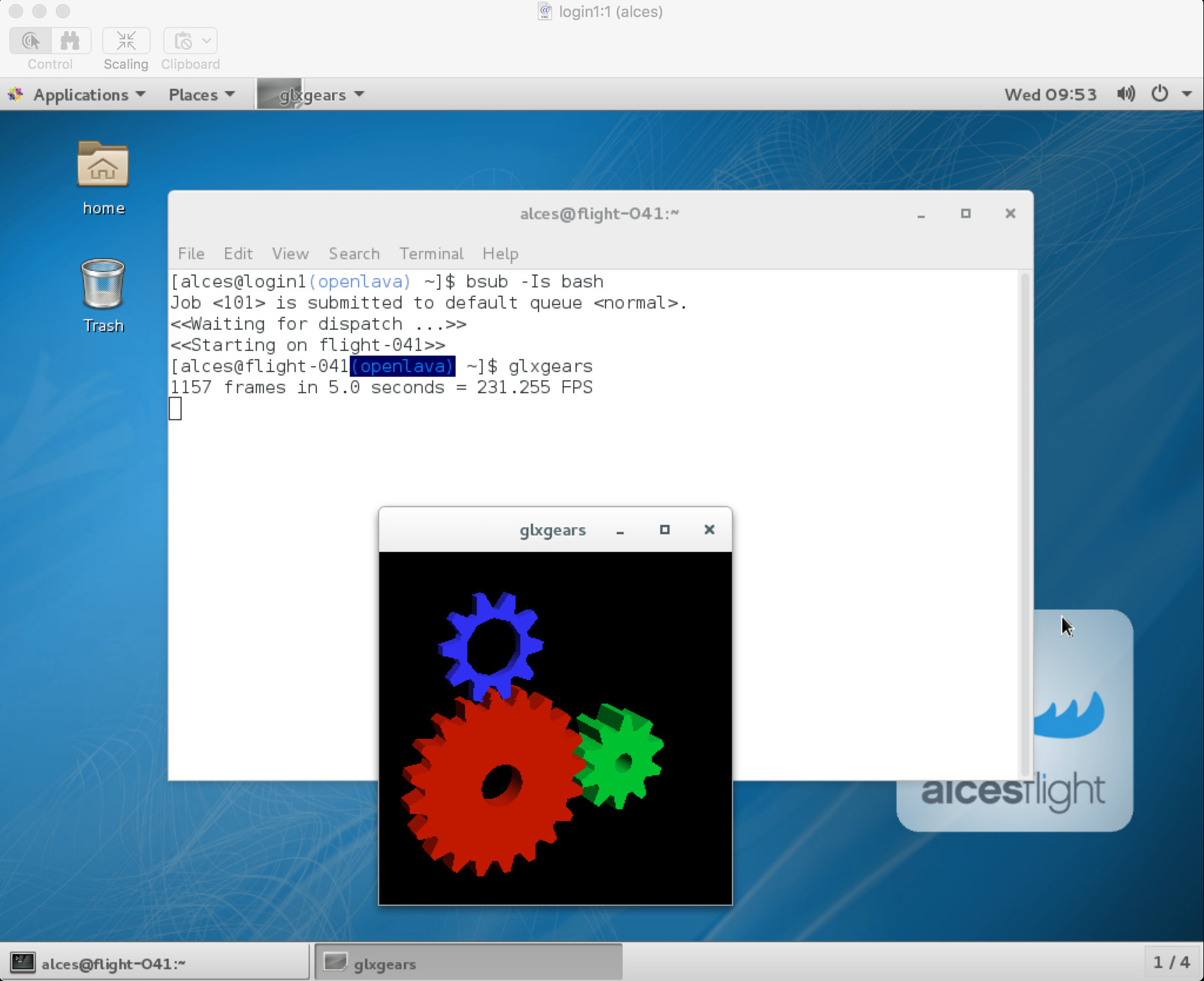
When you’ve finished running your application, simply type logout, or press Ctrl+D to exit the interactive job.
Submitting a batch job¶
Batch (or non-interactive) jobs allow users to leverage one of the main benefits of a cluster scheduler; jobs can be queued up with instructions on how to run them and executed across the cluster while the user does something else. Users submit jobs as scripts, which include instructions on how to run the job - the output of the job (stdout and stderr in Linux terminology) is written to a file on disk for review later on. You can write a batch job that does anything that can be typed on the command-line.
We’ll start with a basic example - the following script is written in bash (the default Linux command-line interpreter). You can create the script yourself using the Nano command-line editor - use the command nano simplejobscript.sh to create a new file, then type in the contents below. This script does nothing more than print some messages to the screen (the
echo lines), and sleeps for 120 seconds. We’ve saved the script to a file called simplejobscript.sh - the .sh extension helps to remind us that this is a shell script, but adding a filename extension isn’t strictly necessary for Linux.
#!/bin/bash -l
echo "Starting running on host $HOSTNAME"
sleep 120
echo "Finished running - goodbye from $HOSTNAME"
Note
We use the -l option to bash on the first line of the script to request a long session. This ensures that environment modules can be loaded as required as part of your script.
Warning
When submitting a batch job script through the bsub command - your job script should be redirected through stdin, for example bsub < myscript.sh. Failing to do so will cause your job to fail.
We can execute the job-script directly on the login node by using the command bash simplejobscript.sh - after a couple of minutes, we get the following output:
Starting running on host login1
Finished running - goodbye from login1
To submit your jobscript to the cluster job scheduler, use the command bsub -o $HOME/jobout.txt < simplejobscript.sh. The job scheduler should immediately report the job-ID for your job; your job-ID is unique for your current Alces Flight Compute cluster - it will never be repeated once used.
[alces@login1(scooby) ~]$ bsub -o $HOME/jobout.txt < simplejobscript.sh
Job <151> is submitted to default queue <normal>.
Note
The -o $HOME/jobout.txt parameter instructs OpenLava to save the output of your job in a file. For example - if you submit a job as the user named alces, your job output will be written to the file /home/alces/jobout.txt.
Warning
If you do not specify a location to save your job output file using the -o option, it will not be not be saved to disk. You can also get a copy of your job output via email by using the parameters -N -u myuser@email-address.com.
Viewing and controlling queued jobs¶
Once your job has been submitted, use the bjobs command to view the status of the job queue. If you have available compute nodes, your job should be shown in RUN (running) state; if your compute nodes are busy, or you’ve launched an auto-scaling cluster and currently have no running nodes, your job may be shown in PEND (pending) state until compute nodes are available to run it.
The scheduler is likely to spread them around over different nodes in your cluster (if you have multiple nodes). The login node is not included in your cluster for scheduling purposes - jobs submitted to the scheduler will only be run on your cluster compute nodes. You can use the bkill <job-ID> command to delete a job you’ve submitted, whether it’s running or still in queued state.
[alces@login1(scooby) ~]$ bsub < simplejobscript.sh
Job <164> is submitted to default queue <normal>.
[alces@login1(scooby) ~]$ bsub < simplejobscript.sh
Job <165> is submitted to default queue <normal>.
[alces@login1(scooby) ~]$ bsub < simplejobscript.sh
Job <166> is submitted to default queue <normal>.
[alces@login1(scooby) ~]$ bkill 165
Job <165> is being terminated
[alces@login1(scooby) ~]$ bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
162 alces RUN normal login1 flight-203 sleep Aug 30 16:15
163 alces RUN normal login1 flight-251 sleep Aug 30 16:15
164 alces PEND normal login1 sleep Aug 30 16:15
166 alces PEND normal login1 sleep Aug 30 16:15
Viewing compute host status¶
Users can use the bhosts command to view the status of compute node hosts in your Flight Compute cluster.
[alces@login1(scooby) ~]$ bhosts
HOST_NAME STATUS JL/U MAX NJOBS RUN SSUSP USUSP RSV
flight-203 ok - 2 0 0 0 0 0
flight-222 ok - 2 0 0 0 0 0
flight-225 ok - 2 0 0 0 0 0
flight-251 ok - 2 0 0 0 0 0
flight-255 closed - 2 2 2 0 0 0
login1 closed - 0 0 0 0 0 0
The bhosts output shows information about the jobs running on each cluster scheduler host. You may also use the -l option to displayed more detailed information about each cluster execution host.
Default resources¶
By default, the OpenLava scheduler sets the default resource limits to “unlimited” if the resource is not specified in your job submission script or command. To promote efficient usage of the cluster scheduler, it is recommended to make use of the scheduler submission directives, which allow you to inform the scheduler how much of each resource a job may require. Informing the scheduler of the required resources will help you to better schedule and backfill jobs. The sections below detail how to inform the scheduler how much of various resource your job may require.
Providing job-scheduler instructions¶
Most cluster users will want to provide instructions to the job-scheduler to tell it how to run their jobs. The instructions you want to give will depend on what your job is going to do, but might include:
- Naming your job so you can find it again
- Controlling how job output files are written
- Controlling when your job will be run
- Requesting additional resources for your job
Job instructions can be provided in two ways; they are:
On the command line, as parameters to your
bsubcommande.g. you can set the name of your job using the
-J <job name>option:
[alces@login1(scooby) ~]$ bsub -J sleepjob < simplejobscript.sh
Job <167> is submitted to default queue <normal>.
[alces@login1(scooby) ~]$ bjobs
JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME
167 alces PEND normal login1 sleepjob Aug 30 16:36
For batch jobs, job scheduler instructions can also be included in your job-script on a line starting with the special identifier
#BSUB.e.g. the following job-script includes a
-Jinstruction that sets the name of the job:
#!/bin/bash -l
#BSUB -J job_name
echo "Starting running on host $HOSTNAME"
sleep 120
echo "Finished running - goodbye from $HOSTNAME"
Including job scheduler instructions in your job-scripts is often the most convenient method of working for batch jobs - follow the guidelines below for the best experience:
- Lines in your script that include job-scheduler instructions must start with
#BSUBat the beginning of the line- You can have multiple lines starting with
#BSUBin your job-script, with normal script lines in-between.- You can put multiple instructions separated by a space on a single line starting with
#BSUB- The scheduler will parse the script from top to bottom and set instructions in order; if you set the same parameter twice, the second value will be used
- Instructions provided as parameters to the
bsubcommand override values specified in job-scripts- Instructions are parsed at job submission time, before the job itself has actually run. That means you can’t, for example, tell the scheduler to put your job output in a directory that you create in the job-script itself - the directory will not exist when the job starts running, and your job will fail with an error.
- You can use dynamic variables in your instructions (see below)
Dynamic scheduler variables¶
Your cluster job scheduler automatically creates a number of pseudo environment variables which are available to your job-scripts when they are running on cluster compute nodes, along with standard Linux variables. Useful values include the following:
$HOSTNAMEThe Linux hostname of the compute node running the job%JThe job-ID number for the job$IFor task array jobs, this variable indicates the task number; for normal jobs, the variable is set to zero.
Simple scheduler instruction examples¶
Here are some commonly used scheduler instructions, along with some examples of their usage:
Setting output file location¶
To set the output file location for your job, use the -o <filename> option - both standard-out and standard-error from your job-script, including any output generated by applications launched by your script, will be saved in the filename you specify. If no job output directory is specified in your scheduler directives, the files will attempt to write to the directory the job script was submitted from. By default, output files will be saved in the same directory as your job was submitted from - use the pwd command to check on the directory name before submitting your job-script.
By default, the scheduler stores data relative to the job submission directory - but to avoid confusion, we recommend specifying a full path to the filename to be used. Although Linux can support several jobs writing to the same output file, the result is likely to be garbled - it’s common practice to include something unique about the job (e.g. it’s job-ID) in the output filename to make sure your job’s output is clear and easy to read.
Note
The directory used to store your job output file must exist and be writeable before you submit your job to the scheduler. Your job may fail to run if the scheduler cannot create the output file in the directory requested.
Warning
OpenLava does not support using the $HOME or ~ shortcuts when specifying your job output file. Use the full path to your home directory instead - e.g. if you are logged into your cluster as the alces user, you could store the output file of your job in your home-directory by using the scheduler instruction #BSUB -o /home/alces/myjoboutput.%J.txt
For example; the following job-script includes a -o instruction to set the output file location:
#!/bin/bash -l
#BSUB -o sleepjob_output.%J.out
echo "Hello from $HOSTNAME"
sleep 60
echo "Goodbye from $HOSTNAME"
In the above example, assuming the job was submitted as user alces and was given job-ID number 24, the scheduler will save output data from the job in the filename /home/alces/sleepjob_output.24.out.
Waiting for a previous job before running¶
You can instruct the scheduler to wait for an existing job to finish before starting to run the job you are submitting with the -w <dependency_expression> instruction. This allows you to build up multi-stage jobs by ensuring jobs are executed sequentially, even if enough resources are available to run them in parallel. For example, to submit a job that will only start running once job number 102 has finished, use the following example submission command:
[alces@login1(scooby) ~]$ bsub -w "done(101)" < myjobscript.sh
The job will then stay in pending status until the specified job number has reached completion. You can check the dependency exists by running the following command, which shows more detailed information about a job:
[alces@login1(scooby) ~]$ bjobs -l <job-ID>
Job Id <102>, User <alces>, Project <default>, Status <PEND>, Queue <normal>, Command <#!/bin/bash -l;sleep 120>
Wed Aug 31 11:33:42: Submitted from host <login1>, CWD <$HOME>, Dependency Condition <done(101)>;
PENDING REASONS:
Job dependency condition not satisfied: 1 host;
You can also depend on multiple jobs finishing before running a job - using the following example command;
[alces@login1(scooby) ~]$ bsub -w "done(103) && done(104)" < myjobscript.sh
Job <105> is submitted to default queue <normal>.
[alces@login1(scooby) ~]$ bjobs -l 105
Job Id <105>, User <alces>, Project <default>, Status <PEND>, Queue <normal>, Command <#!/bin/bash -l;sleep 120>
Wed Aug 31 11:45:27: Submitted from host <login1>, CWD <$HOME>, Dependency Condition <done(103) && done(104)>;
PENDING REASONS:
Job dependency condition not satisfied: 1 host;
Running task array jobs¶
A common workload is having a large number of jobs to run which basically do the same thing, aside perhaps from having different input data. You could generate a job-script for each of them and submit it, but that’s not very convenient - especially if you have many hundreds or thousands of tasks to complete. Such jobs are known as task arrays - an embarrassingly parallel job will often fit into this category.
A convenient way to run such jobs on a cluster is to use a task array, using the bsub command together with the appropriate array syntax -J name[array_spec] in your job name. Your job-script can then use pseudo environment variables created by the scheduler to refer to data used by each task in the job. For example, the following job-script uses the $LSF_JOBINDEX variable to echo its current task ID to an output file. The job script also uses the scheduler directive -o <output> to specify an output file location. Using the variable substitutions %J and %I in the output specification allows the scheduler to generate a dynamic filename based on the job ID (%J) and array job index (%I) - generating the example output file /home/alces/output.24.2 for job ID 24, array task 2.
#!/bin/bash -l
#BSUB -o /home/alces/output.%J.%I
echo "I am $LSB_JOBINDEX"
You can submit an array job using the syntax -J "jobname[array_spec]" - for example to submit an array job with the name array and 20 consecutively numbered tasks - you could use the following job submission line together with the above example jobscript:
bsub -J "array[1-20]" < array_job.sh
By including the following line, a separate output file for each task of the array job, for example task 22 of job ID 77 would generate the output file output.74.22 in the submission directory.
#BSUB -o output.%J-%I
Array jobs can easily be cancelled using the bkill command - the following example shows various levels of control over an array job:
bkill 77- Cancels all array tasks under the job ID
77 bkill "77[1-100]"- Cancels array tasks
1-100under the job ID77 bkill "77[22]"- Cancels array task 22` under the job ID
77
Requesting more resources¶
By default, jobs are constrained to the default set of resources - users can use scheduler instructions to request more resources for their jobs. The following documentation shows how these requests can be made.
Running multi-threaded jobs¶
If users want to use multiple cores on a compute node to run a multi-threaded application, they need to inform the scheduler - this allows jobs to be efficiently spread over compute nodes to get the best possible performance. Using multiple CPU cores is achieved by specifying the -n <number of cores> option in either your submission command or the scheduler directives in your job script. The -n option informs the scheduler of the number of cores you wish to reserve for use. For example; you could specify the option -n 4 to request 4 CPU cores for your job.
Note
If the number of cores specified is more than the total amount of cores available on the cluster, the job will refuse to run and display an error
Running Parallel (MPI) jobs¶
If users want to run parallel jobs via a message passing interface (MPI), they need to inform the scheduler - this allows jobs to be efficiently spread over compute nodes to get the best possible performance. Using multiple CPU cores across multiple nodes is achieved by specifying the -n <number of cores> option in either your submission command or the scheduler directives in your job script. If the number of cores requested is more than any single node in your cluster, the job
will be appropriately placed over two or more compute hosts as required.
For example, to use 64 cores on the cluster for a single application - the instruction -n 64 can be used. The following example shows launching the Intel Message-passing MPI benchmark across 64 cores on your cluster. This application is launched via the OpenMPI mpirun command - the number of threads and list of hosts are automatically assembled by the scheduler and passed to the MPI at runtime. This jobscript loads the apps/imb module before launching the
application, which automatically loads the module for OpenMPI. Using the scheduler directive -R "span[ptile=8]" allows you span each of the requested cores in the -n 64 directive over as many nodes as are required, for example -n 64 -R "span[ptile=8] would spread the job over 8 nodes, using 8 cores across each node - totaling 64 nodes.
#!/bin/bash -l
#BSUB -n 64 # Define the total number of cores to use
#BSUB -R "span[ptile=8]" # Number of cores per node
#BSUB -o imb.%J # Set output file to imb.<job-ID>
#BSUB -J mpi_imb # Set job name
module load apps/imb # Load required modules
machinefile=/tmp/machines.$$
for host in $LSB_HOSTS; do # generate node list
echo $host >> $machinefile
done
mpirun --prefix $MPI_HOME \
--hostfile $machinefile \
$(which IMB-MPI1) PingPong # run IMB
rm -fv $machinefile # remove node list
The job script requests a total of 64 cores, requesting 8 cores on each compute host. The -R "span[ptile=8]" option can be used to specify the number of cores required per compute host.
Warning
Users running OpenLava may need to explicitly provide the number of MPI processes you wish to spawn as an option to the mpirun command. For example, to run 64 processes, the command mpirun -np 64 would be used. The above example job script demonstrates several additionally required options in the mpirun command - most importantly -np <number> and -npernode <number>. These options define the total number of MPI processes, as well as the number of MPI processes per node to spawn.
Note
If the number of cores specified is more than the total amount of cores available on the cluster, the job will not be scheduled to run and will display an error.
Requesting more memory¶
In order to promote best-use of the cluster scheduler - particularly in a shared environment, it is recommended to inform the scheduler the maximum required memory per submitted job. This helps the scheduler appropriately place jobs on the available nodes in the cluster.
You can specify the maximum amount of memory required per submitted job with the -M [KB] option. This informs the scheduler of the memory required for the submitted job. The following example job script can be used to submit a job which informs the scheduler your job may use up to 512MB of memory:
#!/bin/bash
#BSUB -o sleep.%J
#BSUB -M 512000
Requesting a longer runtime¶
In order to promote best-use of the cluster scheduler, particularly in a shared environment, it is recommended to inform the scheduler the amount of time the submitted job is expected to take. You can inform the cluster scheduler of the expected runtime using the -W [hh:mm:ss] option. For example - to submit a job that runs for 2 hours, the following example job script could be used:
#!/bin/bash -l
#BSUB -J sleep
#BSUB -o sleep.%J
#BSUB -W 02:00:00
Users can view any time limits assigned to running jobs using the command bjobs -l [job-ID]:
Job Id <117>, User <alces>, Project <default>, Status <RUN>, Queue <normal>, Command <#!/bin/bash -l;sleep 120>
Wed Aug 31 13:31:18: Submitted from host <login1>, CWD <$HOME>;
RUNLIMIT
120.0 min of ip-10-75-1-
Wed Aug 31 13:31:25: Started on <ip-10-75-1-96>, Execution Home </home/alces>, Execution CWD </home/alces>;
Wed Aug 31 13:31:39: Resource usage collected.
MEM: 5 Mbytes; SWAP: 346 Mbytes
PGID: 27789; PIDs: 27789 27791 27794 2785
Further documentation¶
This guide is a quick overview of some of the many available options of the OpenLava cluster scheduler. For more information on the available options, you may wish to reference some of the following available documentation for the demonstrated OpenLava commands;
- Use the
man bjobscommand to see a full list of scheduler queue instructions- Use the
man bsubcommand to see a full list of scheduler submission instructions- Online documentation for the OpenLava scheduler is available here